
C 프로그래밍 언어는 컴퓨터 과학 및 소프트웨어 개발 분야에서 매우 중요한 위치를 차지하고 있습니다. 이 글에서는 C 언어의 역사, 기본 구조, 그리고 오늘날 컴퓨팅 환경에서 그 중요성에 대해 깊이 있게 탐구하겠습니다.
C 언어의 역사와 발전
초기 개발과 역사적 배경
C 언어는 1972년, AT&T 벨 연구소의 켄 톰슨과 데니스 리치에 의해 개발되었습니다. 이 언어의 탄생 배경은 유닉스 운영 체제의 개발과 깊은 연관이 있습니다. 유닉스 시스템의 기반이 되는 많은 프로그램이 C로 작성되었으며, 이는 오늘날에도 많은 운영 체제의 커널 개발에 C 언어가 널리 사용되는 이유 중 하나입니다.
역사적인 이정표
- 1969년: B 언어 개발, 이는 BCPL에서 파생된 것.
- 1972년: 데니스 리치가 B 언어를 개선하여 C 언어 탄생.
- 1983년: ANSI X3.159-1989로 C 언어의 첫 공식 표준화 진행.
- 1999년: C99 표준안 발표.
- 2011년: C11 표준안 발표.
- 2018년: C17 표준안 발표.
C 언어의 특징
C 언어는 구조적 프로그래밍을 지원하며, 높은 이식성과 효율성을 제공합니다. 초기 개발 당시, PDP-11의 어셈블리 언어로 구현된 유닉스 운영체제와 밀접한 관련이 있었고, 이후 struct 자료형의 도입으로 C 언어는 더욱 강력해졌습니다.
C 언어의 기본 구조
C 프로그래밍 언어의 기본 구조를 이해하는 것은 프로그래밍 학습에 있어 중요한 첫 걸음입니다. 아래는 가장 기본적인 C 프로그램 예제로, “Hello World”를 출력하는 코드입니다.
#include <stdio.h> // 표준 입출력 헤더 파일 포함
int main() { // 메인 함수 정의
printf("Hello World!"); // 화면에 "Hello World!" 출력
return 0; // 프로그램 종료
}이 예제는 C 프로그래밍의 기본적인 구조를 보여줍니다: 프로그램은 하나 이상의 함수로 구성되며, 그 중 main() 함수는 프로그램의 시작점입니다. 여기서 #include <stdio.h>는 표준 입출력 관련 기능을 사용하기 위해 필요한 헤더 파일을 포함시킵니다.

현대 컴퓨팅에서의 C 언어의 중요성
C 언어는 시스템 프로그래밍뿐만 아니라 응용 프로그램 개발에도 광범위하게 사용됩니다. 그 이유는 다음과 같습니다:
- 이식성과 효율성: C 프로그램은 다양한 플랫폼에서 쉽게 실행할 수 있으며, 실행 속도가 빠릅니다.
- 시스템 접근성: C 언어는 하드웨어에 접근하고 제어하는 데 필요한 기능을 제공합니다.
- 기반 기술: 현대의 많은 운영 체제, 임베디드 시스템, 그리고 컴퓨터 아키텍처는 C 언어로 개발되었습니다.
결론적으로, C 프로그래밍 언어는 컴퓨터 과학의 기초이자, 현대 기술 개발의 핵심 도구 중 하나입니다. 그것은 강력한 기능과 유연성을 제공함으로써 다양한 분야에서의 소프트웨어 개발을 가능하게 합니다.
C언어의 진화 K&R C부터 C17까지
C 프로그래밍 언어는 컴퓨터 과학과 소프트웨어 개발의 핵심 요소로서, 시간이 지남에 따라 계속해서 발전해왔습니다. C 언어의 중요한 역사적 발전 단계를 살펴보며, K&R C에서 시작하여 최신 표준인 C17까지 언어가 어떻게 진화해왔는지 탐구하겠습니다.
K&R C: 기초를 다지다
초창기 C 언어의 표준화
1978년, 브라이언 커니핸과 데니스 리치는 “The C Programming Language”라는 책을 출간했습니다. 이 책은 C 언어를 사용하는 프로그래머들 사이에서 “K&R”로 알려지게 되었고, 비공식적으로나마 오랫동안 C 언어의 규격 역할을 했습니다. K&R C는 C 언어의 첫 번째 버전으로, 여러 중요한 기능을 도입하였습니다:
- 표준 입출력 라이브러리
long int와unsigned int자료형- 복합 대입 연산자의 형태 변경 (
=-에서-=로)
이러한 변경은 C 언어의 명확성과 표현력을 개선하는 데 중요한 역할을 했습니다.
C99: 기능 확장과 국제화
개정된 표준의 등장
1999년, C 언어는 ISO/IEC 9899:1999, 일명 C99 표준을 통해 크게 개정되었습니다. C99는 C 언어의 기능을 대폭 확장하였으며, 몇 가지 주요 개선 사항은 다음과 같습니다:
- 국제적 문자 세트에 대한 확장된 지원
- 기술적 교정과 세부 사항의 교정
C99는 C 언어의 범용성과 유연성을 한층 더 높여, 개발자들이 더 복잡한 프로그램을 효과적으로 작성할 수 있게 했습니다.
C11: 현대화와 새로운 기능
최신 표준의 발표
2011년에는 C 언어의 다음 큰 업데이트인 ISO/IEC 9899:2011, 혹은 C11이 발표되었습니다. C11은 여러 중요한 새 기능을 도입하였으며, 이는 C 언어를 현대 컴퓨팅 환경에 더욱 적합하게 만들었습니다. C11의 주요 특징으로는 다음이 포함됩니다:
- 멀티스레딩 지원의 향상
- 개선된 메모리 관리 기능
- 익명 구조체와 공용체의 도입
C11은 C 프로그래밍 언어의 발전을 계속 이끌며, 개발자들에게 더 많은 표현력과 효율성을 제공합니다.
C17: 안정성과 호환성의 강화
최근 표준의 채택
C 언어의 최신 버전인 C17(ISO/IEC 9899:2018)은 2018년에 발표되었습니다. 이 표준은 주로 기존의 표준을 정제하고, 안정성과 호환성을 더욱 강화하는 데 중점을 두었습니다. C17은 큰 변화를 도입하기보다는, C 언어의 기초를 더욱 견고하게 다지는 역할을 했습니다.
C 언어 문법: 연산자, 변수형, 그리고 소스코드 구조
C 언어는 컴퓨터 프로그래밍에서 가장 기본적이고 중요한 언어 중 하나입니다. 그 문법은 프로그래머에게 강력한 표현력과 유연성을 제공합니다. C 언어의 핵심 문법 요소인 연산자, 변수형, 그리고 소스코드의 구조에 대해 살펴보겠습니다.
C 언어의 소스코드 구조
C 언어는 free-form 언어로, 포트란 77과 같은 언어와 달리, 소스코드 내에서 공백을 자유롭게 사용할 수 있습니다. 이는 코드의 가독성과 구조를 개선하는 데 도움이 됩니다. C 프로그램은 일반적으로 하나 이상의 함수로 구성되며, main() 함수는 프로그램의 시작점입니다.
연산자
C 언어는 다양한 종류의 연산자를 지원합니다. 이들은 크게 다음과 같은 카테고리로 나눌 수 있습니다:
산술 연산자
+: 덧셈-: 뺄셈*: 곱셈/: 나눗셈%: 나머지
관계 연산자
==: 동등!=: 불일치<: 미만>: 초과<=: 이하>=: 이상
논리 연산자
&&: 논리곱(AND)||: 논리합(OR)!: 논리 부정(NOT)
대입 연산자
=: 기본 대입+=,-=,*=,/=,%=등: 복합 대입 연산자
증감 연산자
++: 증가--: 감소
변수형
C 언어에서 변수는 데이터를 저장하는 기본 단위입니다. 다양한 데이터 유형을 지원하여 프로그램의 다양한 요구 사항을 충족시킵니다.
기본 자료형
int: 정수형float,double: 부동소수점 숫자char: 문자
수정자
signed,unsigned: 부호 있는/없는 정수long,short: 정수의 크기 조정
구조체 (struct)
- 서로 다른 자료형의 변수를 하나의 단위로 묶을 수 있습니다. 예를 들어, 사람의 이름, 나이, 성별을 하나의 구조체로 정의할 수 있습니다.
C 언어 포인터의 이해와 활용
C 언어에서 포인터는 프로그래밍의 가장 강력한 특징 중 하나입니다. 포인터를 통해 메모리 주소를 직접 다루고, 변수의 값에 간접적으로 접근할 수 있습니다. 포인터의 기본적인 개념, 선언 및 사용 방법에 대해 자세히 살펴보겠습니다.
포인터란?
포인터는 메모리 주소를 저장하는 변수입니다. 즉, 포인터는 다른 변수의 위치를 가리키며, 이를 통해 간접적으로 해당 변수의 값을 읽거나 수정할 수 있습니다.
포인터 선언
포인터 변수를 선언하는 방법은 선언하고자 하는 변수의 자료형 뒤에 별표(*)를 붙이는 것입니다. 이 별표는 포인터임을 나타내며, 선언문에서 자료형과 변수명 사이 어디에 위치하든 상관없습니다.
int *p; // 정수형 변수의 주소를 저장할 포인터
char *c; // 문자형 변수의 주소를 저장할 포인터
double *d; // 실수형 변수의 주소를 저장할 포인터포인터 사용
포인터를 사용할 때는 선언할 때와 달리, *를 사용하지 않고 변수명만으로 포인터를 사용할 수 있습니다. 포인터를 통해 변수의 값을 간접적으로 접근하려면, * 연산자(역참조 연산자)를 사용합니다.
주소 연산자(&)
변수의 주소를 얻기 위해서는 주소 연산자 &를 변수명 앞에 붙입니다.
int var = 10;
int *ptr = &var;위 코드에서 ptr은 var의 주소를 저장합니다. 따라서 ptr은 var를 가리키는 포인터가 됩니다.
역참조 연산자(*)
포인터를 통해 가리키는 변수의 값을 접근하려면, 역참조 연산자 *를 사용합니다.
int value = *ptr; // ptr이 가리키는 변수 var의 값을 value에 저장
*ptr = 20; // ptr이 가리키는 변수 var의 값을 20으로 변경포인터의 중요성
포인터는 다음과 같은 경우에 유용하게 사용됩니다:
- 함수의 인자로 큰 데이터 구조를 전달할 때 복사를 피하고, 메모리 주소만 전달하여 성능을 향상시킵니다.
- 함수에서 여러 값을 반환하거나, 호출된 함수에서 호출하는 함수의 변수를 직접 수정할 수 있습니다.
- 동적 메모리 할당을 통해 실행 시간에 메모리 크기를 결정할 수 있습니다.
포인터는 C 언어 프로그래밍에서 강력한 기능을 제공합니다. 메모리의 직접적인 관리를 가능하게 하며, 프로그램의 효율성과 유연성을 크게 향상시킵니다. 포인터의 올바른 사용은 C 언어의 숙련도를 나타내는 중요한 지표 중 하나이며, 포인터를 통해 메모리와 변수를 보다 효과적으로 다룰 수 있습니다.
C 언어와 메모리 관리: 세부 분석
C 언어를 사용하여 개발할 때, 프로그램의 메모리 관리는 중요한 고려 사항입니다. 운영 체제(OS)와 CPU가 프로그램을 실행하기 위해 메모리를 어떻게 할당하고 사용하는지 이해하는 것은 효율적인 프로그래밍에 필수적입니다. C 언어 프로그램의 메모리 할당 영역, 변수 유형 및 메모리 맵에 대해 자세히 살펴보겠습니다.
메모리 할당 영역
C 언어로 개발된 프로그램은 메모리를 다음과 같이 몇 가지 주요 영역으로 나누어 사용합니다:
정적 변수 (Static Variables)
static키워드를 사용하여 선언된 변수들입니다.- 프로그램 시작 시에 한 번만 초기화되며, 프로그램이 종료될 때까지 메모리에 남아 있습니다.
동적 변수 (Dynamic Variables)
- 힙(Heap) 영역에 위치합니다.
malloc,calloc,realloc등의 함수를 사용하여 동적으로 메모리를 할당 받습니다.- 사용 후에는
free함수를 통해 메모리를 반납해야 합니다.
자동 변수 (Automatic Variables)
- 함수 또는 블록 내에서 선언되며, 스택(Stack) 영역에서 자동으로 메모리가 할당됩니다.
- 해당 함수 또는 블록의 실행이 종료되면 자동으로 메모리가 해제됩니다.
메모리 맵과 변수
C 언어 프로그램의 컴파일 과정에서 생성되는 실행 파일은 다양한 변수 유형을 포함하며, 이들은 메모리 상에서 특정 방식으로 배치됩니다.
초기치를 갖는 변수
- 변수가 선언될 때 초기값을 갖습니다.
- 메모리의 데이터 세그먼트 또는 초기화된 데이터 영역에 저장됩니다.
초기치가 없는 변수
- 초기값을 갖지 않고 선언된 변수들입니다.
- BSS 세그먼트(초기화되지 않은 데이터 영역)에 저장됩니다.
상수 데이터
- 프로그램 코드에서 사용되는 리터럴 상수들입니다.
- 텍스트 세그먼트 또는 상수 데이터 영역에 저장됩니다.
메모리 관리의 중요성
메모리 관리는 프로그램의 성능과 안정성에 직접적인 영향을 미칩니다. 잘못된 메모리 관리는 메모리 누수, 오류 및 다양한 실행 문제를 일으킬 수 있습니다. 따라서 개발자는 다음 사항에 주의해야 합니다:
- 동적으로 할당된 메모리는 반드시 해제되어야 합니다.
- 스택 영역의 메모리는 자동으로 관리되지만, 스택 오버플로우를 방지하기 위해 지역 변수의 사용을 신중하게 고려해야 합니다.
- 정적 변수는 프로그램 전체에서 접근 가능하기 때문에, 사용에 있어 주의가 필요합니다.
C 언어에서의 메모리 관리는 프로그램의 효율성, 안정성 및 성능을 결정짓는 핵심 요소입니다. 프로그램의 메모리 사용 패턴을 이해하고, 각 변수 유형과 메모리 영역의 특성을 적절히 활용하는 것이 중요합니다. 이를 통해 개발자는 메모리 누수 없이, 더 빠르고 안정적인 프로그램을 개발할 수 있습니다.
C 표준 라이브러리: 핵심 구성 요소
C 언어는 다양한 표준 라이브러리를 제공합니다. 이 라이브러리들은 프로그래머가 일반적인 프로그래밍 작업을 수행할 때 필요한 다양한 기능을 포함하고 있으며, 개발 과정을 효율적으로 만들어줍니다. C 표준 라이브러리의 주요 구성 요소와 그 기능을 소개합니다.
C 표준 라이브러리 헤더 파일
C 표준 라이브러리는 ISO/IEC 9899 표준에 정의되어 있으며, 여러 헤더 파일로 구성되어 있습니다. 각 헤더 파일은 특정 기능 집합을 제공합니다.
기본 라이브러리 헤더
<assert.h>: 프로그램의 가정을 테스트하고, 실패 시 진단 메시지를 출력합니다.<ctype.h>: 문자 분류 및 변환 함수를 제공합니다 (예: 대문자를 소문자로 변환).<errno.h>: 시스템 오류 번호를 정의합니다.<limits.h>: 기본 자료형의 한계값을 정의합니다.<math.h>: 수학 함수와 상수를 제공합니다.<stdbool.h>(C99): 논리 자료형을 지원합니다.<stddef.h>: 여러 유용한 형과 매크로를 정의합니다.<stdint.h>(C99): 고정 너비 정수형을 정의합니다.<stdio.h>: 표준 입출력 함수를 제공합니다.<stdlib.h>: 메모리 할당, 프로그램 제어, 변환, 난수 생성 등의 함수를 제공합니다.<string.h>: 문자열 처리 함수를 제공합니다.<time.h>: 날짜와 시간 처리 함수를 제공합니다.
C99에서 추가된 라이브러리 헤더
<complex.h>: 복소수 처리를 위한 함수와 매크로를 정의합니다.<fenv.h>: 부동소수점 환경 제어를 위한 함수와 매크로를 정의합니다.<inttypes.h>: printf와 scanf의 형식 지정자와 고정 너비 정수의 변환을 위한 함수를 정의합니다.<tgmath.h>: 일반화된 수학 함수의 형 변환을 제공합니다.
국제화 및 확장 문자 처리를 위한 헤더
<locale.h>: 로케일 관련 함수를 제공합니다.<wchar.h>,<wctype.h>: 국제화 및 확장 문자 처리를 위한 함수와 매크로를 정의합니다.
C 표준 라이브러리는 프로그래머가 다양한 작업을 효율적으로 수행할 수 있도록 돕습니다. 이러한 라이브러리는 표준화되어 있기 때문에 다양한 개발 환경에서 일관된 방식으로 사용될 수 있습니다. 프로그램을 개발할 때 이러한 라이브러리의 기능을 최대한 활용하는 것은 시간을 절약하고 코드의 안정성과 이식성을 높이는 데 도움이 됩니다.
C 언어 개발 도구: 개요 및 특징
C 언어 개발을 위한 다양한 도구들이 있으며, 이들은 개발자가 효율적으로 코드를 작성하고, 컴파일하며, 디버깅할 수 있도록 지원합니다. GCC, make, Cygwin, MinGW, 이클립스, 그리고 마이크로소프트 비주얼 스튜디오 등 주요 C 언어 개발 도구들에 대해 살펴보겠습니다.
GCC (GNU Compiler Collection)
- 소개: 유닉스 계열(리눅스 포함)에서 주로 사용되는 컴파일러 모음입니다. C, C++, Objective-C, Fortran, Java, Ada 등 다양한 프로그래밍 언어를 지원합니다.
- 특징: 리눅스 OS 컴파일, 응용 프로그램 개발, 임베디드 시스템 개발 등에 널리 사용됩니다.
make
- 소개: 소프트웨어 빌드 자동화 도구입니다. 파일 간 의존성을 관리하며, Makefile에 정의된 대로 컴파일 및 빌드 과정을 자동으로 수행합니다.
- 특징: 프로그램의 컴파일 및 링크 과정을 단순화하고 자동화하여 개발 시간을 단축시킵니다.
Cygwin
- 소개: 윈도우 환경에서 유닉스 계열의 개발 도구와 프로그램을 사용할 수 있도록 하는 소프트웨어입니다.
- 특징: 윈도우에서 GCC를 비롯한 유닉스 기반 도구와 응용 프로그램을 실행할 수 있게 해줍니다.
MinGW (Minimalist GNU for Windows)
- 소개: 윈도우에서 네이티브 실행 파일을 생성할 수 있는 GCC 포트입니다.
- 특징: Cygwin과 달리 윈도우의 네이티브 API와 직접 상호 작용하며, 윈도우 환경에서 가볍고 빠르게 동작합니다.
이클립스 (Eclipse IDE for C/C++ Developers)
- 소개: 다양한 프로그래밍 언어를 지원하는 통합 개발 환경(IDE)입니다. C/C++ 개발을 위한 환경도 제공합니다.
- 특징: 리눅스와 윈도우에서 GCC와 연동하여 사용할 수 있으며, 코드 편집, 빌드, 디버깅 등 다양한 개발 도구를 제공합니다.
마이크로소프트 비주얼 스튜디오
- 소개: 마이크로소프트에서 개발한 윈도우 기반의 통합 개발 환경입니다.
- 특징: C, C++, C# 등 다양한 언어를 지원하며, 윈도우 API, MFC, DirectX 등 윈도우 개발에 필요한 다양한 라이브러리와 툴킷을 포함하고 있습니다.
각 개발 도구는 그 특성과 사용 환경에 따라 장단점이 있으며, 프로젝트의 요구 사항과 개발자의 선호에 따라 적절한 도구를 선택하여 사용할 수 있습니다. C 언어 개발에 있어 이러한 도구들은 코드 작성부터 디버깅, 빌드, 배포에 이르기까지 전 과정을 지원하며, 개발의 생산성과 효율성을 크게 향상시킵니다.
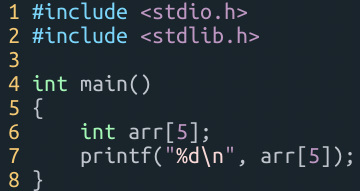
소프트웨어 개발에서의 디버깅 방법
디버깅은 프로그램 개발 과정에서 발생하는 오류를 찾아내고 수정하는 중요한 단계입니다. 효과적인 디버깅은 개발 시간을 단축하고, 소프트웨어의 품질을 향상시킬 수 있습니다. 주로 두 가지 방법으로 디버깅이 이루어집니다: IDE를 통한 소스 수준에서의 디버깅과 로깅을 통한 디버깅입니다.
IDE를 통한 소스 수준 디버깅
IDE(통합 개발 환경)는 소스 코드를 단계별로 실행하며 오류를 찾아낼 수 있는 다양한 도구를 제공합니다. 대표적인 기능은 다음과 같습니다:
- Break Point: 프로그램 실행을 특정 지점에서 중단시키고, 그 시점에서의 변수 값, 메모리 상태 등을 검사할 수 있습니다.
- Step Over/Into: 코드를 한 줄씩 실행하며, 필요에 따라 함수 내부로 들어가거나 넘어갈 수 있습니다.
- 변수 감시: 특정 변수의 값이 변경되는 시점을 추적하고, 해당 변수의 값이 어떻게 변화하는지 확인할 수 있습니다.
로깅을 통한 디버깅
로깅은 프로그램의 실행 과정에서 발생하는 다양한 이벤트를 기록하는 방법입니다. 주로 printf와 같은 함수를 사용하여 내부 변수의 상태나 실행 흐름의 정보를 출력합니다. 로깅은 다음과 같은 환경에서 유용합니다:
- 임베디드 시스템 개발: 고성능의 IDE를 사용할 수 없는 환경에서 UART나 USB를 통해 디버깅 정보를 출력할 수 있습니다.
- 리눅스 커널 개발:
printk함수를 사용하여 커널 로그를 통해 디버깅 정보를 출력할 수 있습니다.
GDB (GNU Debugger)
GDB는 GCC와 함께 사용되는 강력한 디버깅 도구입니다. 유닉스 계열 운영 체제에서 널리 사용되며, 다음과 같은 기능을 제공합니다:
- 응용 프로그램 디버깅: GDB를 사용하여 실행 중인 프로그램의 실행을 제어하고, 변수 값을 검사하거나 변경할 수 있습니다.
- 원격 디버깅: 네트워크를 통해 다른 시스템에서 실행 중인 프로그램을 디버깅할 수 있습니다. 이는 임베디드 시스템 개발에서 특히 유용합니다.
- 커널 디버깅: KGDB와 같은 도구를 사용하여 리눅스 커널을 디버깅할 수 있습니다.
IDE 디버깅 도구
비주얼 스튜디오, 이클립스와 같은 현대적인 IDE들은 GDB와의 연동을 포함하여 소스 수준에서의 디버깅을 지원합니다. 이러한 IDE는 개발자가 코드를 보다 효율적으로 이해하고, 오류를 빠르게 찾아내고 수정할 수 있도록 다양한 디버깅 도구를 제공합니다.